#7: Succeeding, despite mistakes; Software continues to eat the world; Ignoring piracy for profit; Information compression
June 18 - June 25, 2021

Succeeding, despite mistakes
It's easy to assign successful people's success to the things they did, but their success is in fact a mix of:
Succeeding because some of the things they did, and;
Succeeding despite some of the things they did.
…successful people make decisions based on a specific context, and people later copy the decisions without taking that context into account.
When emulating successful people, try to understand their process and context; don’t just replicate their actions.
Software is eating the world, at John Deere
Jahmy [Hindman, CTO at John Deere] told me that John Deere employs more software engineers than mechanical engineers now. (source)
This [trend] implies continued (or increasing) demand for :
Chips; the chips and GPU shortage is affecting John Deere too (disclosure: Long Intel & TSMC)
Software engineers, particularly AI and data scientists
Security and cloud computing (a lot of this data is being stored and processed in the cloud). Further, managing and processing data is not the core competency for companies like John Deere, hence this should benefit the higher level providers such as Snowflake. (disclosure: Long Snowflake & Amazon)
Internet connectivity in rural areas; good for Starlink, though John Deere has currently partnered with AT&T
Separately, the interview has a lot of discussion about Right to Repair, and how John Deere and Apple have a roughly similar position.
Allowing piracy is a type of pricing discrimination
Microsoft (pirated Windows/Office), Netflix (ignoring password sharing), Autodesk etc. all allow for some amount of “piracy”, as an unacknowledged strategy.
Many people have written about this, but here’s a nice summary from LibertyRPF:
[Microsoft] have a huge installed base of pirated Windows and Office software, and despite the lost license revenue, it still brought them benefits because it helps with their network effect (file formats), platform value (more potential customers/users for software built on the Windows API), and importantly, it sucks oxygen away from competitors. It’s harder for them to sell their product when they’re competing with both the paid and a free pirated version of the dominant OS/app.
That oxygen-sucking one is prob similar to how Netflix thinks about all the password-sharing. They may not be paying us, but at least they are watching us instead of a competitor, and forming the habit, which increases the chances that they’ll pay later (either because they get tired of being on someone else’s account or because Netflix tightens the screws on the practice).
Information compression
Alexandr Wang of scale.ai wrote about organization overheads (Dunbar’s number?). He starts with:
One oft-cited reason organizations get less efficient as the number of people increases is “communication overhead". It’s a simple model. As a team grows, you spend a greater percentage of time communicating (it scales with n-squared), so you become less efficient.
And then proposes:
While it might be true, I think the far more salient reason is that information compression is incredibly hard.
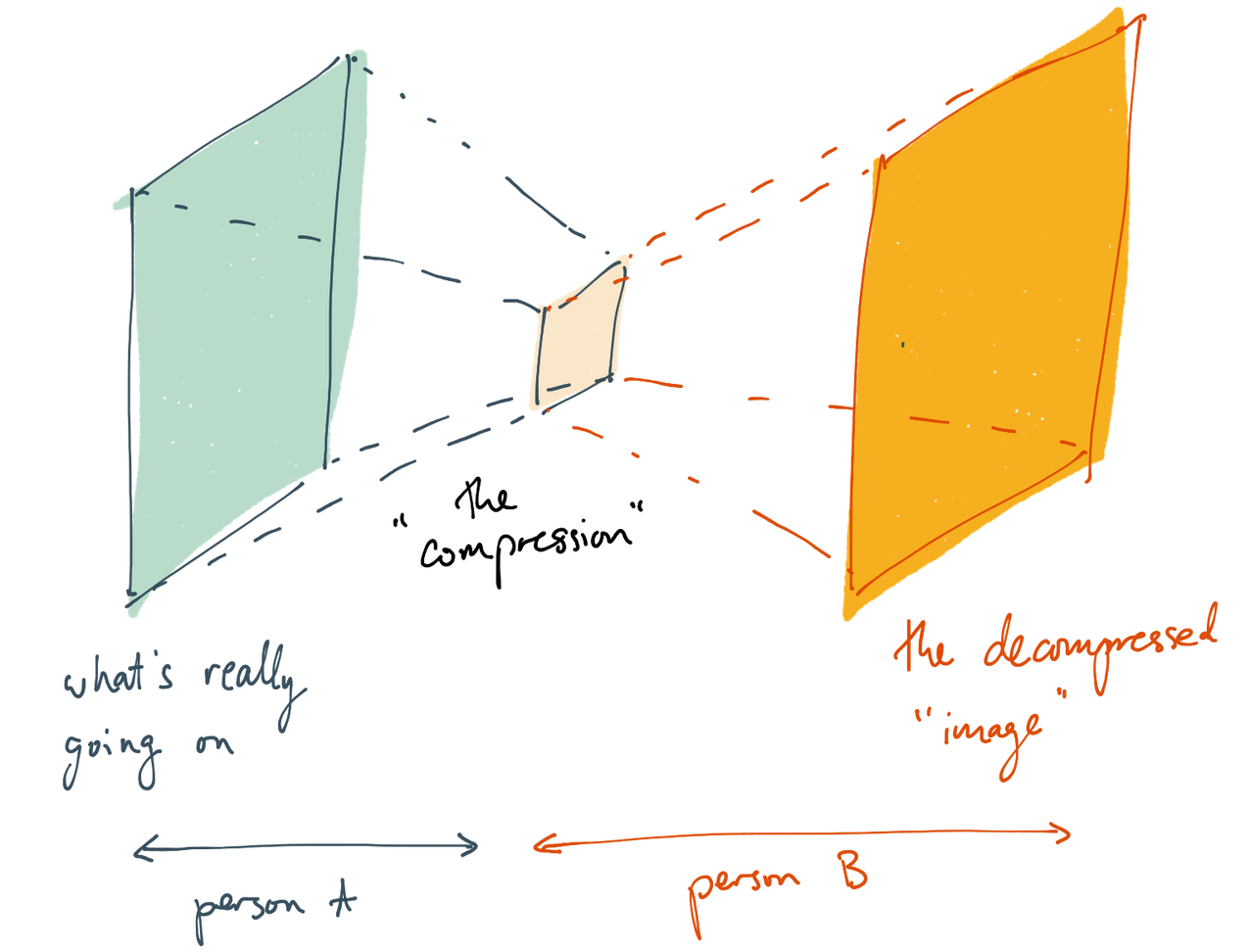
This process of translating the mental image of a complex system to something human-readable (usually words or pictures) is information compression, and what Person B then understands from that message (“the compression”) is the decompressed image.
Ideas, which are often very complex, have to pass through the very narrow window of human language, and often all the nuance is lost.
Put another way, nobody is telling the full truth. Mostly by omission, and mostly unintentionally.
Another interesting diagram is for the “decompression function”, which combines the compressed message, shared context and person B’s priors together, including all of their biases:

You can start to see why a small startup (<5 people) can be so efficient. Everybody is seeing everything else that’s happening, both internally and with the customer. So, the shared context is very strong, both internally and with the customer.
The solution to these information compression woes are tight-knit teams who bring the customer as close to the code as possible.
The ultimate hack is to not rely on compressions at all. If you spend the time to actually feel the pain of the problem and deeply understand it, then you don’t need to rely on some lousy compression and you can solve the problem head-on.
The solutions he describes don’t scale to large organizations in my opinion, but the root problem that he has identified is very real.